有编码经验的小伙伴一定知道,String类在实际编码过程中会经常使用到,但是你真的了解String类吗?
先来看看几个常见的问题吧:
为什么String类是不可变,如此设计的目的?
为什么有人说 String str2 = new String("Hello"); 会创建了2个对象?
String, StringBuffer 和 StringBuilder的区别 ?
为什么拼接字符串时不推荐使用“+”拼接?
带着这些问题,我们一起来深入学习一下String类吧。
1、String类的定义String类是一个引用类型(Reference Type),它用于表示由字符组成的字符串。在Java中,字符串被视为一个对象而不是基本数据类型。
不是基本类型这一点其实很好证明,直接去看一眼String类的源码就行,下图为源码截图(所有源码截图均为JDK1.8):
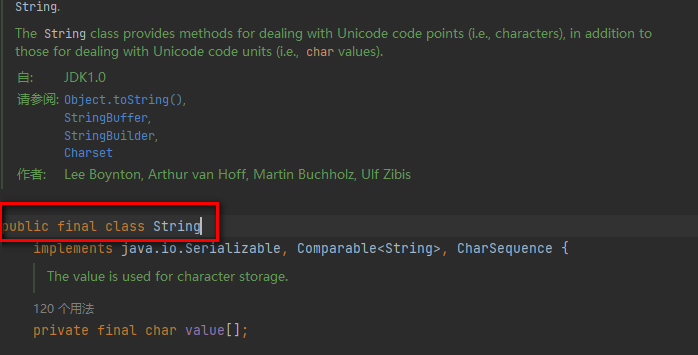
从源码截图中可以看出String 类的声明,从源码里面看String里面实际上是用的一个 char 数组来存储的字符(JDK9+ 已改为 byte数组),
我觉得可以把String理解成 char 的另一高级包装类(这个说法仅个人看法,不一定准确)。其他包装类详情可见这篇 基础知识-03 基本类型对应之包装类 。
Java中的基本类型只有这8种(byte、short、int、long、float、 double、char、boolean)详情可见这篇 基础知识-02 数据基本类型。
2、String类常用的方法 方法名语法功能描述示例先来看看String源码:

通过截图中红框我们可以知道,String类保存字符串的value 数组是一个由 private final 修饰的变量,有此可知String 对象被创建之后它的内容就不能再被修改。
我们再来看看String类的replace方法(方法有点多,仅以replace举例):
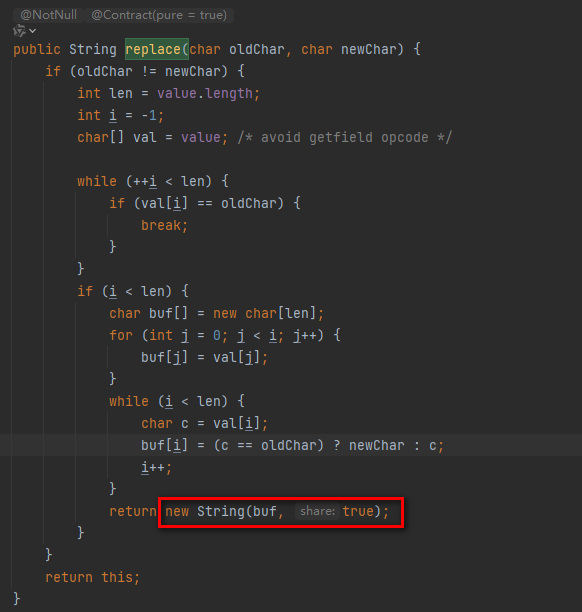
由截图源码可知String类的replace方法的返回新new的一个String对象。
所有看起来像是对字符串进行修改的操作实际上都会返回一个新的 String 对象,而原来的对象保持不变。
为什么String类要设计为不可变呢?
关于这个问题,或许只有设计者才能最精准地阐释当初的设计初衷。不过结合 Java 的特性与实际应用场景,我个人比较认同以下几点原因,也欢迎大家补充其他见解:
安全性:
不可变对象天然适合于多线程环境,因为它们的状态不能被改变,所以在并发访问时不需要考虑同步问题。这减少了并发编程中的复杂性和潜在的错误。
在涉及安全敏感的应用程序中,如网络连接、密码处理等,不可变字符串可以防止数据被意外或恶意地修改。
简化编程模型:
由于不可变性,任何对字符串的操作都会返回一个新的字符串实例,而不是修改原始实例。这种行为使得理解和预测代码的行为更加简单和直观。
哈希表的关键支持:
String 常被用作 HashMap、HashSet 等集合的键(Key)。哈希表的工作依赖于键的哈希值稳定性 —— 如果 String 是可变的,修改其内容会导致哈希值变化,这会破坏哈希表的存储结构,导致无法正确查询、删除元素。不可变性保证了字符串的哈希值在创建后永不改变,使其成为可靠的哈希键。
字符串常量池的基础:
字符串常量池(String Pool)的核心是复用相同内容的字符串以节省内存。如果 String 是可变的,当一个字符串被修改时,所有引用它的变量都会受到影响,常量池的复用机制就会失效。不可变性保证了常量池中的字符串一旦创建就不会被修改,确保了复用的安全性。
安全性与持久化:
在某些情况下,比如序列化或在网络上传输对象时,不可变对象更容易管理和确保一致性,因为你不用担心对象状态的变化。
4、String Pool - 字符串常量池我们先来看看定义:Java中的字符串常量池(String Pool,也称为字符串池)是一种特殊的内存区域,用于存储字符串常量。也是 JVM 为了优化字符串使用而设计的一种内存结构,用于存储字符串字面量并实现复用,核心目的是减少内存消耗和提高性能。
核心特性
存储内容
主要存储字符串字面量(如 "abc")和通过 intern() 方法加入的字符串对象引用(JDK 7+)。
位置
JDK 6 及之前:位于永久代(PermGen)。
JDK 7 及之后:迁移至堆内存(Heap),更便于垃圾回收。
复用机制
相同内容的字符串在常量池中只会保存一份,多个引用可以共享这个实例,避免重复创建相同内容的字符串对象。
字面量加载
当 JVM 加载类时,会经历加载、验证、准备、解析、初始化等阶段。在解析阶段,JVM 会对 class 文件中constant_pool表的符号引用进行解析,将其中的字符串字面量(符号引用)转换为直接引用。
此时,JVM 会检查字符串常量池:
若池中已存在相同内容的字符串,则直接复用其引用;
若不存在,则在常量池中创建该字符串对象,并将引用存入池中。
何为字符串字面量?如 String s = "abc"; 或者 String s = new String("abc"),JVM 会先检查常量池:若已存在 "abc",则直接让 s 指向常量池中的该对象。
若不存在,则在常量池创建 "abc" 并让 s 指向它。
对于通过new String("abc")创建的对象,其中的"abc"字面量仍会在类加载的解析阶段进入常量池,而new操作只是在堆中创建一个新的字符串对象(复制常量池中的内容)。
intern() 方法的作用
对于通过 new String(...) 创建的堆中字符串对象,调用 intern() 会:
检查常量池是否存在相同内容的字符串。
若存在,返回常量池中的引用。
若不存在,将当前堆对象的引用存入常量池(JDK 7+),并返回该引用。
验证时刻:1 public static void fun0() { 2 String s1 = "hello string pool"; // 字面量 "hello string pool" 加入常量池 3 String s2 = "hello" + new String(" string pool"); // 堆中创建新对象 "helo string pool" 4 String s3 = s2.intern(); // 常量池中已有,返回常量池中的引用 5 System.out.println(s1 == s2); // false s1指向常量池中的 "hello string pool",s2指向堆中的 "hello string pool" 6 System.out.println(s1 == s3); // true s1指向常量池中的 "hello string pool",s3 也指向常量池中的 "hello string pool"; 7 }
执行结果:

1 public static void fun1() { 2 String s = new String("hello") + new String(" string pool"); // 堆中创建新对象 "hello string pool"(常量池尚无 "hello string pool") 3 String s2 = s.intern();// 常量池存入 s 的引用,返回 s 本身 4 System.out.println(s == s2); // true(s 和 s2 指向同一个堆对象) 5 System.out.println(s == "hello string pool"); // true("hello string pool" 字面量现在指向常量池中的 s 引用) 6 }
执行结果:

通过上面2个例子的运行结果证明了字符串常量池工作原理跟我们前面的描述是一致的。
读到这里,相信大家对开头的问题“为什么有人说String str2 = new String("Hello");会创建 2 个对象?”已经有了更准确的理解。
准确讲应该是:
如果常量池中没有 "Hello"
第一步:类加载时,字符串字面量 "Hello" 会被加载到字符串常量池,创建 1 个常量池对象。
第二步:new String(...) 会在堆内存中创建 1 个新的字符串对象,该对象的内容是常量池中 "Hello" 的副本。
此时总共创建 2 个对象(1 个常量池对象 + 1 个堆对象)。
如果常量池中已有 "Hello"
由于常量池中的对象可复用,new String(...) 只会在堆内存中创建 1 个新的字符串对象。
此时总共创建 1 个对象(仅堆对象)。
Java 中的 String、StringBuffer 和 StringBuilder 都是用于处理字符串的类,但它们在可变性、线程安全和性能上有显著区别,主要差异如下:
可变性
String:不可变(Immutable)
字符串一旦创建,其内容无法修改。任何修改操作(如拼接、替换)都会创建新的 String 对象,原对象保持不变。
例:s = s + "a" 会生成新对象,而非修改原字符串。
StringBuffer 和 StringBuilder:可变(Mutable)
内部通过可动态扩容的字符数组存储内容,修改操作(如 append()、insert())直接在原有数组上进行,不会创建新对象(除非需要扩容)。
String:天然线程安全
由于不可变性,多线程并发访问时不会出现数据不一致问题,无需同步机制。
StringBuffer:线程安全
所有方法都被 synchronized 修饰,保证多线程环境下的操作原子性,但会带来额外的性能开销。
StringBuilder:非线程安全
未实现同步机制,性能优于 StringBuffer,但多线程并发修改可能导致数据错乱。
String:性能最差
频繁修改(如循环拼接)会产生大量临时对象,增加 GC 负担,效率低下。
StringBuilder:性能最优
无同步开销,单线程场景下拼接效率最高。
StringBuffer:性能次之
因同步锁的存在,性能略低于 StringBuilder,但高于 String。
在 Java 中,字符串拼接不推荐使用 + 运算符,核心原因与 String 的不可变性以及 + 运算符的底层实现机制直接相关,具体可以从以下角度理解:
String不可变性导致的临时对象爆炸String 是不可变对象(内容一旦创建就无法修改)。
每次使用 + 拼接字符串时,JVM 都必须创建一个新的 String 对象来存储拼接结果,
而原来的字符串对象则会变成垃圾等待回收。
举例:
1 String s = "a"; 2 s += "b"; // 创建新对象 "ab",原 "a" 成为垃圾 3 s += "c"; // 再创建新对象 "abc",原 "ab" 成为垃圾
这种操作在循环中会被放大:如果循环拼接 1000 次,会产生近 1000 个临时对象,不仅占用大量内存,还会触发频繁的垃圾回收(GC),严重影响性能。
“+” 运算符编译时会将“ + ”转换为 StringBuilder 的 append() 操作。但这种优化仅适用于简单场景,在循环中会失效。
1 String result = ""; 2 for (int i = 0; i < 1000; i++) { 3 result += i; // 编译器无法感知循环边界 4 }
编译器会被循环 “误导”,在每次迭代中创建新的 StringBuilder 对象(而非复用一个),相当于执行:
1 // 循环内的等效操作(低效) 2 result = new StringBuilder(result).append(i).toString();
结论:
+ 运算符仅适合编译期可确定的简单拼接(如 "hello" + "world" 会被编译器直接优化为 "helloworld"),但对于动态拼接(尤其是循环中的拼接),+ 会导致大量临时对象创建和 GC 开销,性能极差。
因此,实际开发中应优先使用 StringBuilder(单线程)或 StringBuffer(多线程),而非 + 运算符。
